This page contains technical documentation regarding the Joinup platform. It describes the architecture model on which Joinup is based (data, application, and systems architecture), and provides information concerning Joinup’s API which acts as a SPARQL-endpoint for retrieving information.
Architecture overview
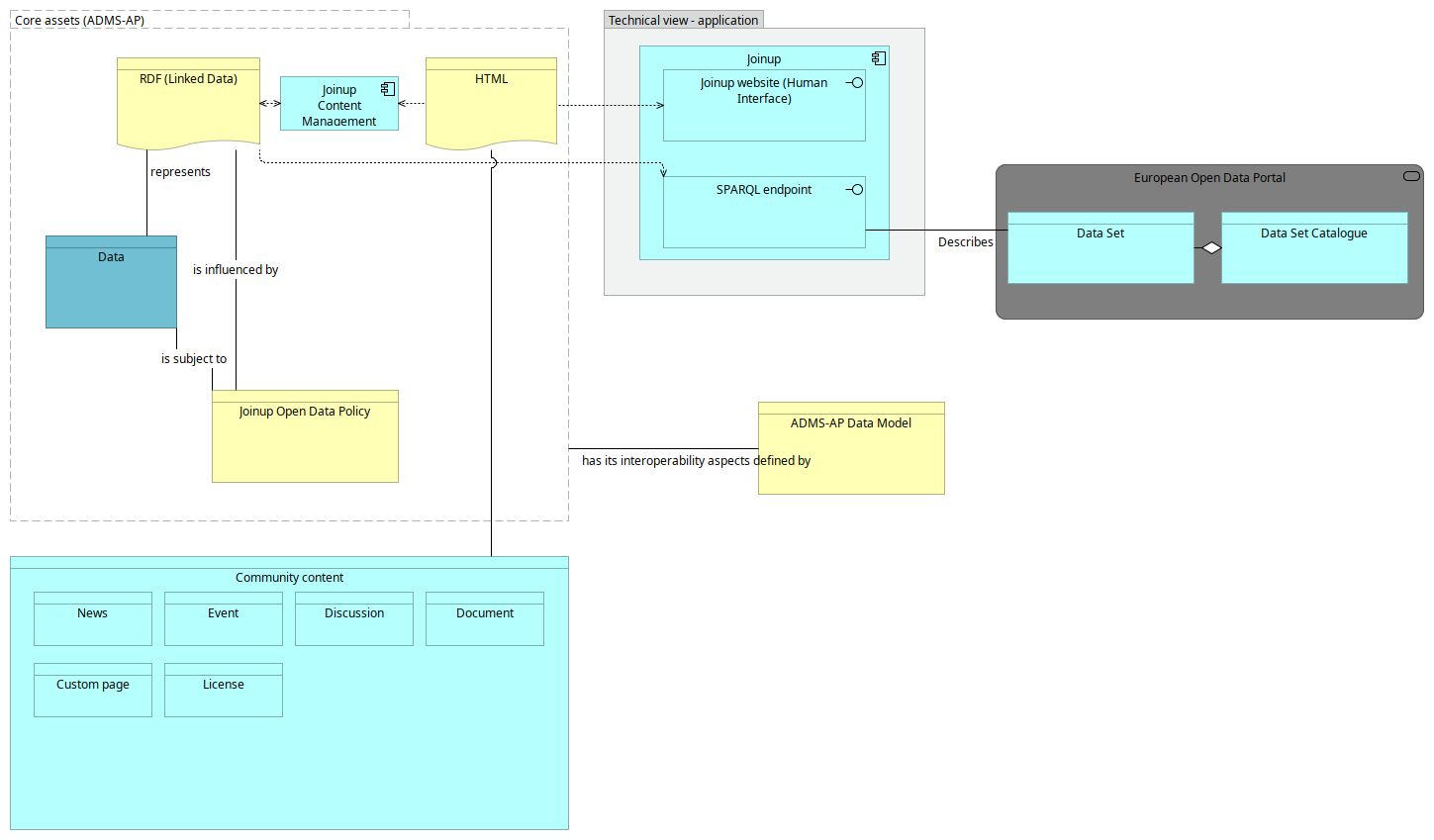
Core assets (ADMS-AP)
The core assets of Joinup use the Asset Description Metadata Schema Application Profile (ADMS-AP) data model, which was developed specifically to foster interoperability between asset catalogues such as Joinup. This data model is under the governance of the Semantic Interoperability Community (SEMIC) action of ISA2.
The ADMS-AP model covers the main concepts of Joinup: Collections (dcat:Catalog), Solutions (dcat:Dataset), Releases (also dcat:Dataset) and Distributions (dcat:Distribution).
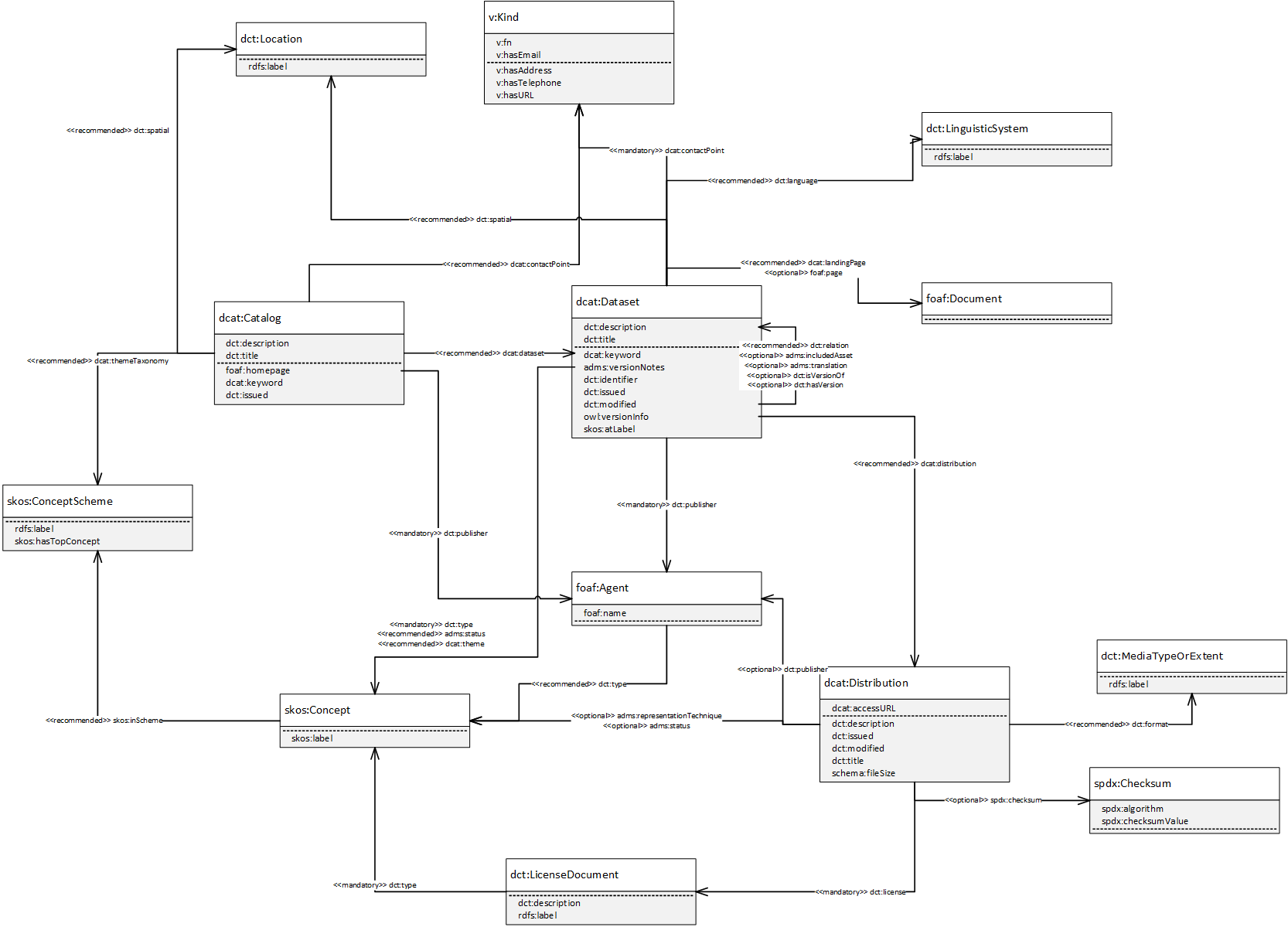
It is based on the Data Catalogue Application Profile (DCAT-AP) model.
Community content
Community content consists of the types of content that can be created in scope of a Collection or Solution, for example News, Events, Discussions, Documents or Custom pages. The governance of the models of these entity types is less strict than of the core assets, as they are not to be harvested from external platforms. They evolve ad-hoc when functionally required.
Drupal
The application stack of Joinup is based on the Open Source Content Management System (CMS) Drupal.
Drupal is a modular system, that allows for functional extension by the means of pluggable modules.
Twin database system
In order to support the harvesting of Solutions from external repositories, and allow working with Linked Data, a graph database (triplestore) is used in addition to the traditional relational database used by the CMS. The triplestore in use is an instance of Virtuoso (Open Source edition).
Custom Drupal modules have been developed to support storing entities as Linked Data: a database driver to support working with the SPARQL protocol, and an implementation of a content entity type to allow mapping entities to an ontology.
Core assets (Collections, Solutions, Releases and Distributions), following the ADMS-AP specification, are stored in the triplestore. All other content (e.g. News, Events, Documents, Discussions etc.) get persisted in the relational database.
Command and Query Responsibility Segregation (CQRS)
Because of the dual database setup in Joinup, where some entities are persisted in a triplestore and others in a relational database, a problem arises: it is no longer possible to query across all entity types.
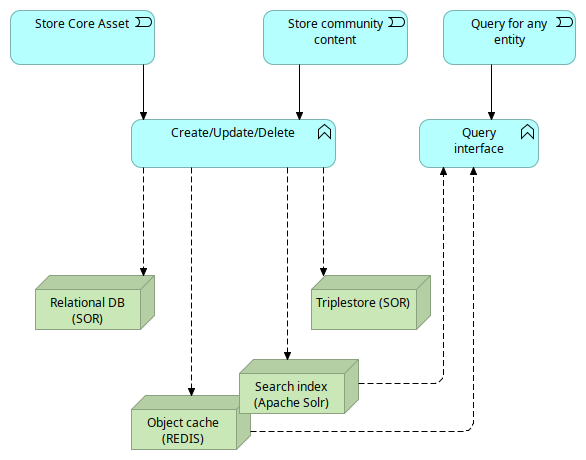
This is solved by a variation on the CQRS pattern. When an entity gets stored, its system of record is kept in either the relational database or the triplestore, depending on its type. Independent of which primary datastore is used, two additional copies of the entity are saved: one in the object store, Redis, which functions as a caching layer for full entity reads, and another in the search index, used for querying. The state of both the object store and the search index can – at all times – be rebuilt using the primary datastores (relational DB and triplestore).
A partial copy of the internal triplestore is used to serve the public SPARQL endpoint, allowing for data reuse.
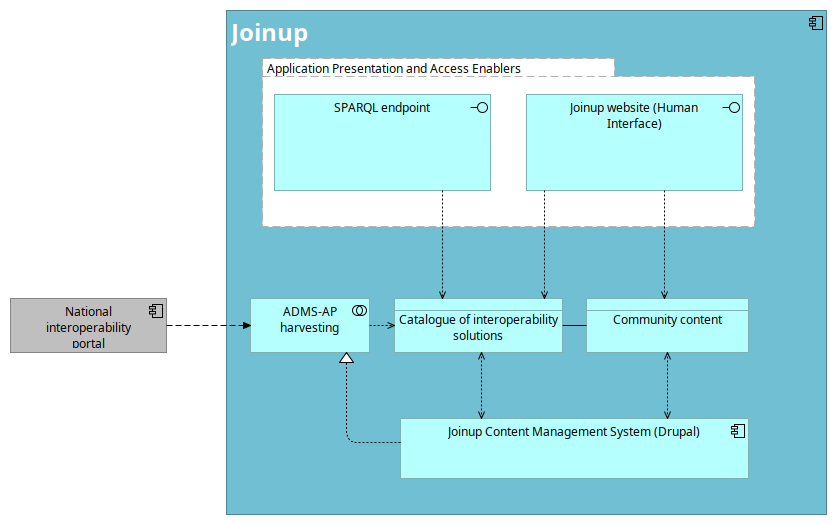
Harvesting
Joinup is a federated catalogue of Solutions: this means that Solutions can be defined in national repositories, and that Joinup forms a unified view over both its ‘native’ Solutions (the ones created through Joinup), as well as the Solutions residing within the national portals. The process of harvesting is explained in more detail here.

Main components
Application server
The application servers consist of Apache servers, running on AWS EC2 instances. These are grouped in an autoscaling group, allowing for dynamic capacity adjustment. The server state is managed with Salt, which is also used to control the application version. The application is packaged in RPM packages, which get installed through Salt. A shared NFS volume manages the files that are uploaded to the CMS (not shown in the diagram).
Search index
The search index is implemented with Apache Solr, using the default schema of the Drupal search API module.
Caching tier
The caching tier is implemented with Redis, which acts as a simple key-value store.
Authoritative database servers
The relational database is a MySQL-compatible managed instance of AWS Aurora, while the triplestore is implemented through an EC2 instance. Both are single instance deployments but receive very low workload due to the application architecture (see CQRS) and are, thus, not at risk of forming a performance bottleneck.
Secondary database servers
The internal triplestore has a partial copy deployed, covering the public data. It is deployed once a day, by restoring a backup of the primary datastore.
The Joinup API: a SPARQL-endpoint
Advanced Joinup users can make use of the SPARQL endpoint to retrieve Joinup information in an automated way. Using the endpoint requires knowledge of the SPARQL query language, the linked data equivalent of SQL.
If you are not familiar with Linked Open Data, both this article and the W3C page describing the SPARQL language specification are good resources to start with.
The SPARQL-endpoint itself can be found here.
As Joinup uses the ADMS-AP data model, it can be very useful to have the specification of ADMS-AP available to know how entities relate to one another.
Let's get started with some example SPARQL queries:
Simple listing of all collections
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dct: <http://purl.org/dc/terms/>
SELECT ?collection_id ?title
WHERE {
?collection_id a dcat:Catalog .
?collection_id dct:title ?title
}
The number of solutions linked to each EIRA ABB
PREFIX dcat: <http://www.w3.org/ns/dcat#> PREFIX dct: <http://purl.org/dc/terms/> PREFIX skos: <http://www.w3.org/2004/02/skos/core#> SELECT ?eira_abb_name count(?solution) as ?number_solutions WHERE { ?solution a dcat:Dataset . OPTIONAL { ?solution dct:type ?eira_abb_uri . ?eira_abb_uri skos:prefLabel ?eira_abb } BIND ( IF( BOUND(?eira_abb), ?eira_abb, "No ABB linked!" ) AS ?eira_abb_name) } GROUP BY ?eira_abb_name ORDER BY DESC(?number_solutions)
The number of distributions linked to each licence
PREFIX dcat: <http://www.w3.org/ns/dcat#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX dct: <http://purl.org/dc/terms/> PREFIX skos: <http://www.w3.org/2004/02/skos/core#> SELECT ?licence_name count(?distribution) as ?distribution_count WHERE { ?distribution a dcat:Distribution . OPTIONAL { ?distribution dct:license ?license_uri . ?license_uri rdfs:label ?licence } BIND ( IF(BOUND(?licence), ?licence, "No licence specified") AS ?licence_name ) } GROUP BY ?licence_name ORDER BY DESC(?distribution_count)
Prefixes
The following namespaces can come in quite handy when writing SPARQL queries against Joinup.
PREFIX adms: <http://www.w3.org/ns/adms#> PREFIX dcat: <http://www.w3.org/ns/dcat#> PREFIX dct: <http://purl.org/dc/terms/> PREFIX foaf: <http://xmlns.com/foaf/0.1/> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX schema: <http://schema.org/> PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX spdx: <http://spdx.org/rdf/terms#> PREFIX v: <http://www.w3.org/2006/vcard/ns#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
Content negotiation
All Joinup content described by ADMS-AP (collections, solutions, releases, distributions, contact information, licences) can not only be retrieved through the endpoint, they also support content negotiation. The persistent URI redirects to the public URL (human readable), so content negotiation is supported on both the URI (data.europa.eu/w21) and the Joinup URL.
An example using curl:
curl -L -H "Accept: text/turtle" http://data.europa.eu/w21/37e87bee-0e8d-4c2a-a762-d7df6427b838