Abstract
MLDCAT-AP aims to describe machine learning models, together with their datasets, Quality measures on the datasets and citing papers. It has been originally developed in collaboration with OpenML.
Table of contents
A lack of standardisation in the machine learning domain
The lack of a standard model for describing machine learning datasets poses a significant challenge in artificial intelligence. Without a consistent approach, discovering, understanding, and reusing existing datasets becomes difficult, resulting in duplicated efforts and inconsistencies in research. This can also make it harder to replicate or build upon previous work, affecting the scientific validity of experiments.
Recognising these challenges, SEMIC, in collaboration with OpenML, aimed to develop a specification that would effectively address these issues. The objective was to create an application profile for describing machine learning datasets and their relevant concepts. This specification would become an extension of DCAT-AP, called MLDCAT-AP.
OpenML
OpenML is a platform that aims to democratise machine learning by providing access to ML test data, including models and results.
The OpenML platform defines several key concepts in the context of machine learning data:
-
Datasets: tabular data with columns and rows with different data types. Support for Deep Learning data, such as audio and video, is being developed.
-
Tasks: this defines the evaluation procedure, the split being used in the experiment, the target to predict and which metric is being optimised.
-
Flows: these contain the algorithm description, dependencies and hyperparameters which affect the way that the model is trained. These flows can be an entire description of how to use the data and build the model with it, or a subset of this process.
-
Runs: runs describe the evaluation of a flow on a task, they store the predictions and add metrics calculated by OpenML to assess the quality of the model.
The platform can be accessed on the web interface to explore the data and the different concepts. The interface of the REST API can also be used. Additionally, packages in the most common languages such as Python, R and Java are available.
Development of the MLDCAT-AP model
The initial analysis involved understanding the current structure used by OpenML. Each dataset is uniquely identified by its dataset ID, which can be found in the URL of the dataset page. Versioning of a dataset is indicated by a version tag. However, this is not reflected in the name of the datasets, which can be the same for different versions. Each dataset has a status, which can be "active," "deactivated," or "in preparation." Additionally, datasets can have features tagged as "ignored" or "row id," which are excluded from programming interfaces and tasks. OpenML covers various task types, such as classification and clustering, and users can create tasks online.
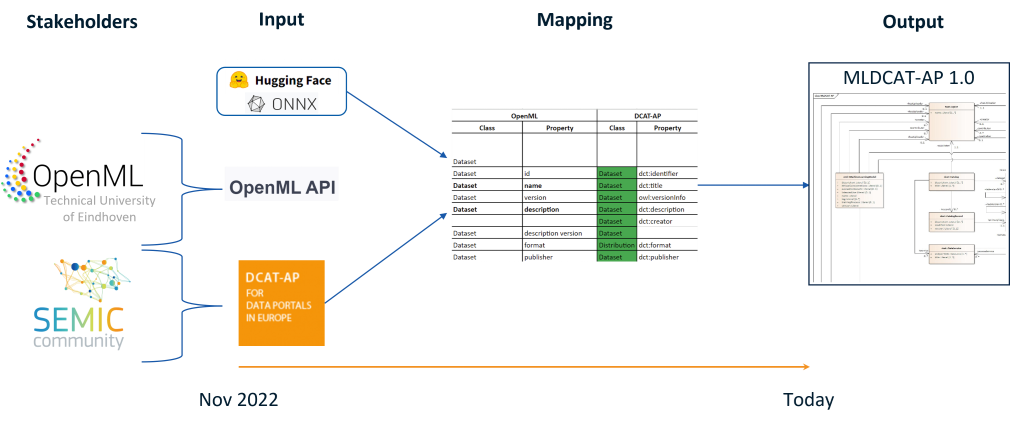
The next step in the pilot was to perform a semantic mapping between the DCAT-AP, Schema.org, OpenML, and META-SHARE models. This mapping resulted in the creation of the MLDCAT-AP model, which includes eight classes from DCAT-AP, 25 customised classes (including classes on quality and measure), and one class called "Machine learning model" created through mapping with Hugging Face, ONNX, and META-SHARE. The MLDCAT-AP model was consistently tested with OpenML to ensure it aligns with the required data concepts.
Results of the OpenML Pilot: MLDCAT-AP 1.0.0
The pilot resulted in the first version of MLDCAT-AP. The model is fully compatible with DCAT-AP while introducing new concepts that are specific to the machine learning space. A key concept that was introduced is the Machine Learning Model class.
The classes in the red box, as depicted in the image below, are repurposed from DCAT-AP. Properties from Dataset, Distribution, and Data Service in DCAT-AP have been aligned with concepts that are found on OpenML datasets and the OpenML API. Some specific examples include ‘keyword’ and ‘download URL’.
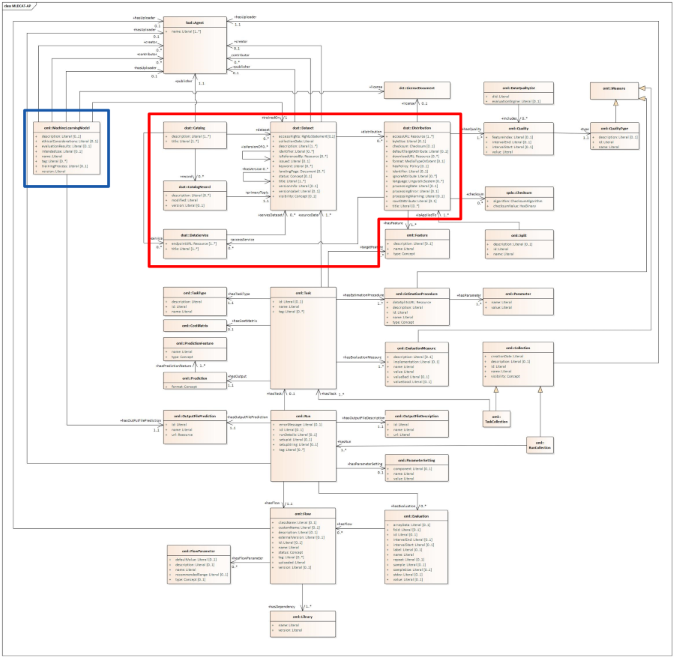
The 'ML Model' class, displayed in the blue box, was constructed based on pre-existing platforms like Hugging Face and ONNX. Properties were included based on the metadata available on these platforms, such as description, name, evaluation results, ethical considerations, intended use, and more.
Finally, classes that are specific to OpenML were added. Examples of these include the previously mentioned Task and Run, but also include EvaluationMeasure, Split, and more.
Similar to DCAT-AP for Open Data Portals it would be possible to programmatically interface with OpenML, that is interacting with OpenML using code through the use of MLDCAT-AP. Automated harvesting of certain data from OpenML becomes possible with a standardised metadata specification describing the data. This would also work the other way around, when MLDCAT-AP is sufficiently integrated with OpenML, tasks from OpenML could be run on datasets modelled according to (ML)DCAT-AP but are not hosted on OpenML.
Further development: MLDCAT-AP 2.0.0
The update from version 1.0.0 to 2.0.0 of MLDCAT-AP involved a comprehensive comparison of different machine learning model repositories. This helped enhance important categories within the framework, such as the Machine Learning Model, Algorithm, Quality-related classes, and Paper. These concepts were added in light of the AI Act in which quality of the used data and the learning method used to train the model play an important role. Additionally, the model was expanded to make it less platform dependent.
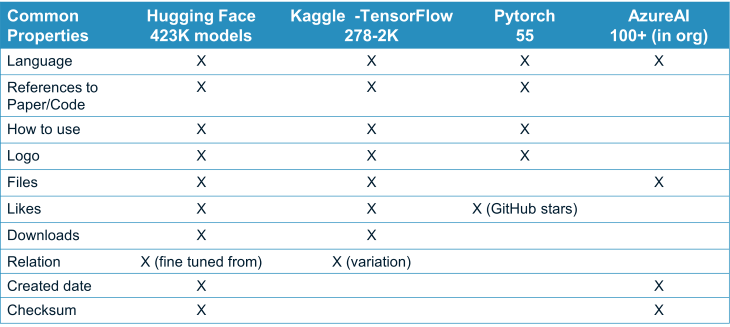
To improve the Machine Learning Model class, four major repositories - Hugging Face, Kaggle, Pytorch, and AzureAI - were analysed. The analysis considered various characteristics of the models, like the language they're written in, relevant academic papers or code, instructions for use, visual symbols, files, and more. This led to the addition of new characteristics to the Machine Learning Model class and the development of new categories like BibliographicReference, ImageObject, and Risk.
The Algorithm class, significant in both machine learning and the context of the AI Act, was refined using a pre-existing framework, the Machine Learning Sailor Ontology (MLSO). This class now includes a list of machine learning algorithms and learning methods, some of which are highlighted in AI regulations.
Quality, an essential aspect of both Datasets and the Machine Learning Model, was addressed by introducing measures from platforms like OpenML, Hugging Face, and Kaggle. This led to the addition of new categories focused on quality in MLDCAT-AP.
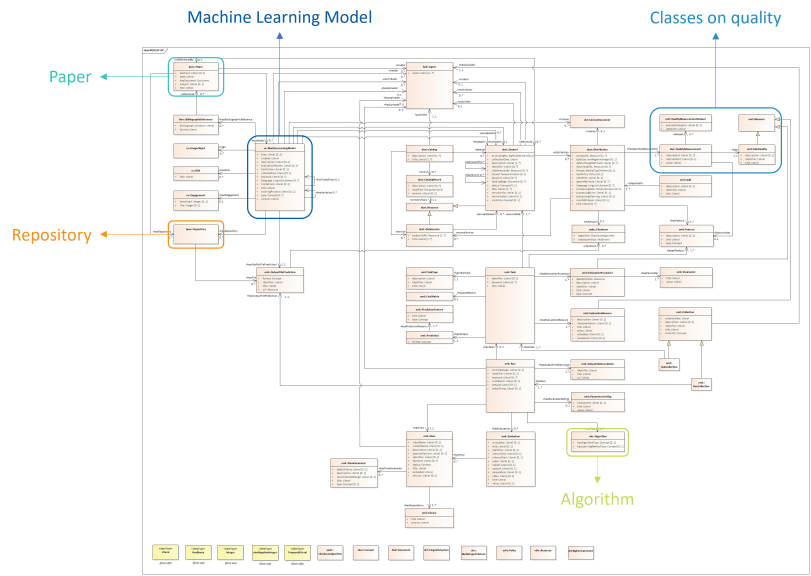
Lastly, the Paper class, which is linked to BibliographicReference, incorporates resources from Linked Paper With Code (LPWC). This class connects academic papers with the datasets, repositories, and models they're associated with, integrating these concepts into MLDCAT-AP.
SEMIC’s role
SEMIC aligned the process with DCAT-AP to ensure the harvestability of OpenML metadata at a European and global scale, in conjunction with initiatives such as data.europa.eu (open data) and Data Spaces. Furthermore, SEMIC proposed the MLDCAT-AP model, which expands beyond pure datasets to include other artefacts such as scripts and experiments. The SEMIC team developed and improved this model with the support of the OpenML team.
The OpenML team provided a deep understanding of the concepts on their platform and how they relate to one another. The SEMIC team focused on the modelling of the specification. In addition, SEMIC provided guidance on interpretation, usage, benefits, and positioning of the model in the machine learning landscape and the associated tooling and implementation.
The end result is a number of REST API endpoints that support at minimum the dataset classes of MLDCAT-AP. While they are not yet fully developed, a demo version is available online.